YaCy
YaCy是一个P2P搜索引擎的开源项目,所谓P2P搜索引擎,就是会把索引分发在网络中,而不是个人所有的机器中。就像P2P下载BT一样,下载的部分文件是来自整个BT网络,而不是全部来自源服务器。同样的,你所爬取的网页建立的索引,会存储在别人的机器上,自己也会存储别人的索引;搜索的时候会使用自己机器上的索引,同样也会使用别人机器上的索引。
听着就觉得是一个很酷的项目,而且他还集成了从爬虫到索引,再到搜索的整个环节,用起来也非常的方便。
但是这个项目当前的限制也不少:
- 中文分词效果不好(对于中文应该采用的是unigram的分词方式)
- 爬虫只能爬取公开的网页,类似那种需要密码登录,和隐私协议的网页是爬不了的
- 支持的query请求种类偏少(例如只有and query没有or query)
不过因为是开源的项目,所以觉得缺少什么功能时,可以自己去实现。Github上的地址在这里,我fork了一份准备改着玩。
目前我在阿里云上部署了一个YaCy, 用的社区模式,也就是P2P模式(也可以设置成一般的非P2P索引模式)。
阿里云上是一台单核,2G内存,20G硬盘,1M带宽的CentOS6.7的机器,原本只有1G内存,看到YaCy的默认内存需要600MB,就额外加大了内存。
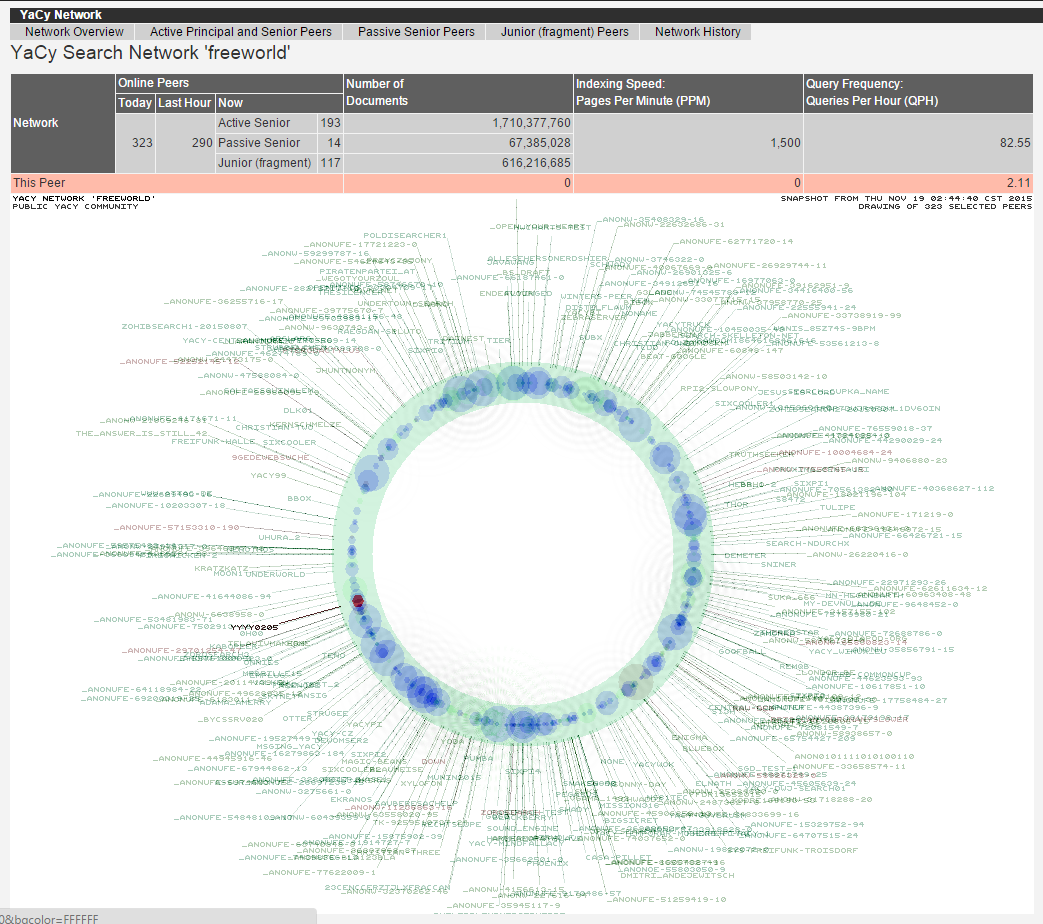
下图是整个YaCy的freeworld网络,每台加入这个P2P索引网络的机器都在这里面(看起来是很酷)。
部署这个系统也很简单
- 从github获取源代码
git clone https://github.com/yacy/yacy_search_server.git
- 用ant进行构建
cd yacy_search_server && ant clean all
- 启动YaCy
./startYACY.sh
成功启动后,可以通过8090端口进行访问。
设置爬虫
在左侧菜单栏点击load web pages, crawler, 然后输入一个你想要的网页地址作为起点。爬虫会遍历每个链接,爬取公开的页面。默认爬取的深度为3层。
如果需要更加复杂的爬虫,可以点左侧菜单中的advanced crawler进行设定。